How to reduce MTTR in cloud Infrastructures using Artificial Intelligence
Resolve incidents faster (and with less stress) in increasingly complex environments.
In today’s cloud environments, everything is connected, and every system depends on another. That’s why reducing MTTR (Mean Time To Resolution) is no longer a “nice to have”– it’s a real necessity for any business.
As architectures evolve, more microservices, integrations, and vendors appear. This brings flexibility, but also increases management complexity. And when something fails, finding the root cause can turn into complete chaos.
For a long time, traditional monitoring was enough. However, in today’s distributed environments, this approach falls short and doesn’t allow you to respond as quickly asthe business needs.
That’s why more and more teams are making the leap to advanced observability powered by artificial intelligence– which not only detects problems but also helps you understand and resolve them much faster.
What is MTTR and why should you care?
MTTR (Mean Time To Resolution) is essentially the average time a team takes to detect, analyze, and resolve an incident.
And although it sounds technical, it has a very real impact on any modern business model that relies heavily on cloud infrastructure:
- The higher this metric → the longer your systems are down
- More negative impact → on revenue, users (experience), and reputation
- More pressure → on technical teams trying to fix things quickly
Reducing MTTR isn’t just about “moving faster,”- it’s about minimizing the impact of problems when they occur and improving your organization’s response capability.
The real problem isn't fixing...it's understanding
In most organizations, the biggest impact on MTTR isn’t technical resolution- it’s diagnosis.
When an incident occurs, teams typically spend most of their time:
- Reviewing multiple tools
- Manually cross-referencing information, logs, metrics, traces, etc.
- Validating hypotheses
- Identifying hidden dependencies
This process is not only slow, but it also heavily depends on the team’s experience.
That’s why the problem isn’t usually a lack of data- it’s a lack of context.
Before vs. after: how AI changes the game
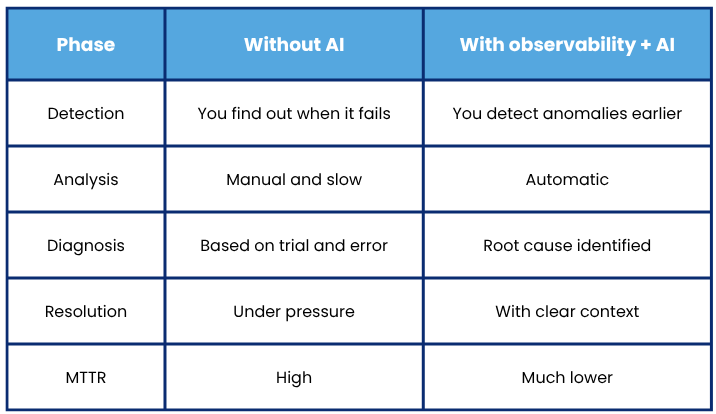
For example, imagine you have an e-commerce site right in the middle of a campaign. Suddenly:
- The website slows down.
- Users start leaving.
- Multiple alerts go off.
Without advanced observability, the team takes hours to find the root cause:: an overloaded database, a bad query, or a service that isn’t responding as it should.
But with observability + AI, the system detects anomalous behavior, connects the data, and points directly to the root cause. s
The result is clear: you go from hours to minutes.
The big shift: from reacting to anticipating
Reducing MTTR is no longer just about reacting faster- it’s about anticipating problems before they escalate.
In many cases, time isn’t lost fixing the incident, but in detecting it, understanding its context, and determining which systems are actually affected.
Artificial intelligence applied to observability makes it possible to tackle these three points simultaneously.
Lessthan3’s technology continuously analyzes metrics, logs, and traces to detect anomalous patterns, correlate events, and provide real-time context.
This drastically reduces the time needed to go from “there’s a problem” to “we know exactly what’s happening”- and we’re about to fix it.
How Lessthan3 helps reduce MTTR
At Lessthan3, the goal isn’t to offer visibility- it’s to help teams operate with greater context and precision.
Our AI-powered predictive observability platform analyzes metrics, logs, and traces in real time to detect patterns, anticipate incidents, and facilitate decision-making from the very first moment.
Thanks to this, it’s possible to:
- Detect incidents in early stages
- Quickly understand what’s happening
- Automatically correlate events across services
- Identify the root cause without long manual processes
- Reduce noise from unnecessary alerts
- Automate responses to recurring incidents
The goal isn’t just to resolve faster- it’s to prevent problems from escalating and affecting the business.
Conclusion
In modern cloud infrastructures, reducing MTTR is one of the biggest operational challenges any organization faces.
System complexity makes traditional approaches no longer sufficient and forces companies to adopt new ways of understanding and managing infrastructure.
The combination of advanced observability and artificial intelligence improves speed, accuracy, and the ability to respond to incidents.
If your team takes too long to identify problems, if alert noise makes it hard to prioritize, or if every incident turns into a complex investigation, the problem probably isn’t a lack of data- isn’t a lack of context.
That’s where solutions like Lessthan3 help make the leap: from reacting to incidents to anticipating them and operating with confidence.
Because today, reducing MTTR isn’t just a technical improvement- isn’t a real competitive advantage.