Optimizing infrastructure without increasing costs
How to improve stability and scalability without paying for more resources
In today’s technology landscape, more resources don’t always translate into better performance.
Many organizations react to system slowdowns by expanding servers, memory, or cloud instances, when the problem often lies in the architectural design, configuration, or infrastructure usage.
Optimizing IT performance isn’t about adding power, it’s about understanding what’s really happening within the system or application and acting strategically. In most cases, significant improvements can be implemented without major investments, simply by adjusting architecture, processes, or usage patterns.
When the system slows down without a clear cause
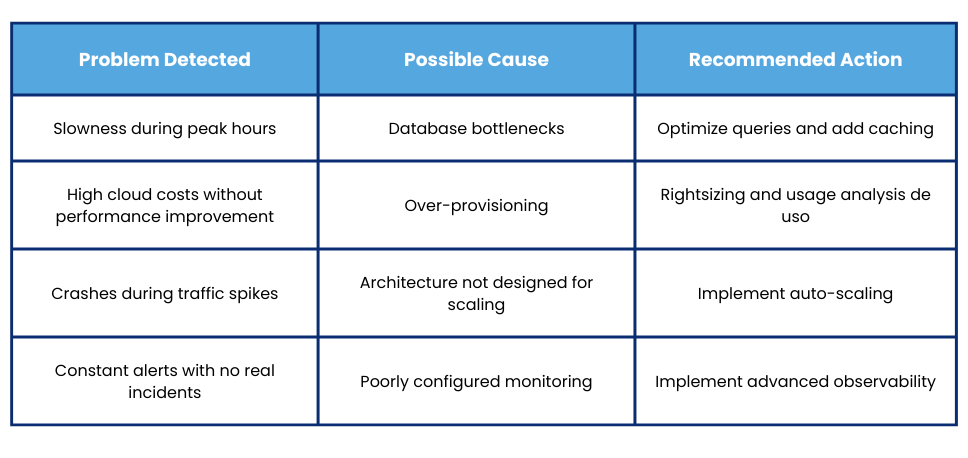
One of the most common symptoms is performance loss during peak hours: slower processes, longer load times, or incidents attributed simply to an increase in users. However, without real metrics and analysis, this explanation often masks deeper problems such as inefficient queries, database bottlenecks, or incorrect cloud configurations.
Slowness is not an inevitable consequence of growth; it’s usually a sign that the infrastructure and its design need strategic review.
What do we really mean by IT performance?
Technology infrastructure performance is measured by its ability to respond quickly, scale in a controlled manner, remain stable under load spikes, scale down if necessary, and ensure continuous availability. When any of these factors fail, the impact is immediately transferred to the business through slower processes, poorer user experience, and loss of operational efficiency and even revenue.
Main factors affecting performance
In most projects, problems arise from a combination of factors such as:
- Outdated or poorly dimensioned architecture
- Poorly optimized database queries
- Lack of caching systems or CDNs
- Over-provisioned or underutilized cloud configurations
- Internal processes that generate unnecessary loads.
Before investing in more resources and infrastructure, it’s essential to identify where the real bottlenecks are or where the investment is actually going.
Strategies to improve performance without over-provisioning
Optimizing performance requires a progressive approach based on objective, real data. Some actions that typically generate the greatest impact are:
- Performing a complete system diagnostic before taking action, using real usage and performance metrics.
- Implementing observability techniques and tools to understand not only what is happening, but why it is happening.
- Optimizing queries, code, and critical processes, especially in databases.
- Introducing intelligent caching mechanisms adapted to usage patterns.
- Reviewing the architecture, simplifying where possible and scaling only where necessary.
Small technical adjustments at these key areas usually generate greater improvements than indiscriminately expanding server resources, GPUs, etc.
Tools that help improve performance
Observability and APM platforms allow you to visualize the real behavior of applications and detect anomalies before they become incidents. Among the most used, in addition to the Lessthan3 Observability platform, are:
- New Relic, Datadog, and Dynatrace for complete observability
- Prometheus and Grafana in cloud and container environments
- CloudWatch and X-Ray in AWS infrastructures
- Google Lighthouse for web performance
The role of DevOps culture in performance
Your infrastructure’s performance and IT effectiveness depend not only on tools or infrastructure, but also on how teams work and are structured. Collaboration between development, operations, and business teams allows for detecting problems earlier, responding faster, and avoiding quick fixes that become permanent.
A mature DevOps culture with good communication facilitates continuous performance improvement and ensures that technology evolves at the pace of the business.
How Lessthan3 can help
At Lessthan3, we approach IT performance improvement for business growth as a continuous optimization process, not simply an expansion of infrastructure resources. Our approach combines technical analysis, strategic vision, and progressive infrastructure improvement, supported by a strong DevOps culture, to archive visible results in just a few weeks. We help organizations to:
- Identify real bottlenecks through data-driven performance analysis
- Review cloud architectures and configurations to optimize costs and efficiency
- Implement observability solutions to detect incidents before they impact the business and to understand what happened
- Define scalability strategies aligned with the company’s actual growth
- Improve DevOps work processes to accelerate incident resolution and reduce downtime
The goal is not to add more infrastructure for the sake of it, but to make existing infrastructure perform at its maximum capacity and get the most out of the investment.
Conclusion
Improving infrastructure performance doesn’t have to be complex or expensive. In most cases, problems with speed, stability, or availability are not due to a lack of resources, but to inefficient configurations, poorly optimized architecture designs, or a lack of visibility into what’s happening within systems and applications.
With the right culture and strategy, continuous analysis, and progressive optimization, technology infrastructure can become a true competitive advantage: faster systems, more controlled costs, and a greater capacity to scale without friction. Your infrastructure should be an engine for growth, not an expense that holds business expansion.