4 errors that are skyrocketing cloud cost without companies knowing it
Where is your budget going? Learn how to control it without slowing down your business growth
Moving to the cloud promises more flexibility, scalability, and cost optimization.
But in practice, many companies find themselves with bills that grow month after month without really understanding why.
And the problem is usually not a single bad decision but something harder to detect: small accumulated errors that go unnoticed, within increasingly complex environments.
Let’s review 4 of the most common ones.
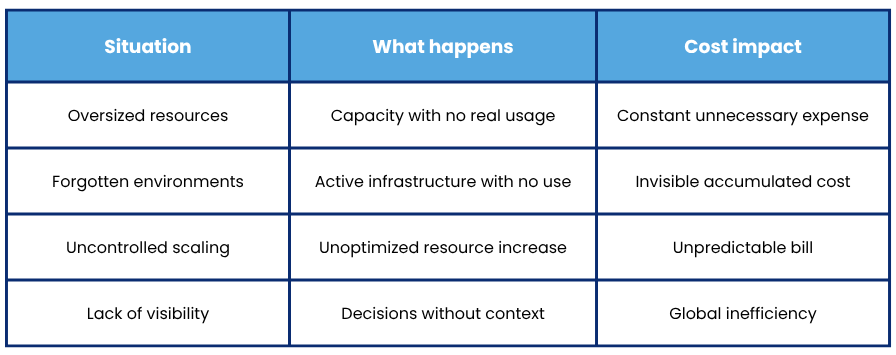
1. Oversized resources that no one reviews
This is one of the most common mistakes, and it happens because many companies allocate more capacity than necessary to avoid performance issues.
Oversized instances, databases with excess capacity, or clusters prepared for workloads that are rarely reached.
This might make sense at the beginning, but if not reviewed, it becomes a constant and unnecessary expense.
The problem is that without clear visibility into actual usage, it’s hard to know what can be adjusted without affecting performance.
2. Forgotten environments that keep consuming
Another classic: development, testing, or staging environments that are created… and never turned off.
Servers that are no longer used, temporary services that remain active, or projects that are abandoned without cleaning up the infrastructure.
Individually they might seem irrelevant, but together they generate a significant impact on the cloud bill.
And since they don’t directly affect production, they often go unnoticed for months.
3. Uncontrolled scaling (and without context)
Autoscaling is one of the great advantages of the cloud, but if poorly managed it can become a problem.
Scaling without understanding what is really happening in the system causes:
- Unnecessary increase of resources
- Duplication of services
- High costs without real performance improvement
Many companies scale “just in case” or as a reaction to alerts, without being sure which component is causing the problem.
Without visibility into system behavior, scaling doesn’t always mean optimizing.
4. Lack of visibility into real consumption
This is probably the most important factor and a management mistake. Many companies know how much they spend on the cloud, but they are not clear on:
- which exact services
- which teams or projects generate it
- which resources are underutilized
- what much of the spending is really necessary
Without this information, optimization becomes a complicated task, based more on assumptions than on real data.
The problem is not the cloud, it's the lack of control
The cloud is not expensive by itself, but it creates problems when you have no control or visibility over how resources are being used.
That’s where unnecessary costs begin to appear, inefficient decisions, and a constant feeling of “we don’t exactly know what’s happening”.
How to start optimizing without overcomplicating things
You don’t need to make big changes all at once.
The first step is usually much simpler: understand what is really happening in your cloud environment.
Some basic actions that make a difference are: reviewing real resource usage, identifying underutilized services, centralizing consumption information, and correlating performance with costs.
When you start having context, optimization stops being a complex task and becomes an ongoing decision.
How Lessthan3 helps
At Lessthan3, we help companies gain a complete view of their cloud infrastructure to detect inefficiencies before they become unnecessary costs.
Our platform analyzes metrics, logs, traces, and system behavior to identify anomalous consumption patterns, underutilized resources, and real optimization opportunities.
The goal is not only to reduce costs, but to do so with context for intelligent optimization aligned with the company’s needs.
For example, by helping to properly size services, eliminate unnecessary resources, or anticipate real scaling needs based on objective data.
Conclusion
The increase in cloud costs is rarely a one-off issue. It is usually the consequence of accumulated small decisions: oversized resources, forgotten environments, scaling without context, or lack of visibility. The good news is that all these problems can be detected and corrected if there is sufficient observability over the cloud environment. And that’s where the real difference comes in: it’s not just about spending less, but about better understanding how your infrastructure works in order to invest where it truly adds value to the business.