Which data does Observability pay attention to to be effective?
- Logs: Detailed records of events within a system, providing information about what happened, when, and why. These records are used for problem analysis, security auditing, and application diagnostics. An example log entry could be as follows: 2025-02-14 12:34:56 ERROR ServiceX – Database connection failed: Timeout
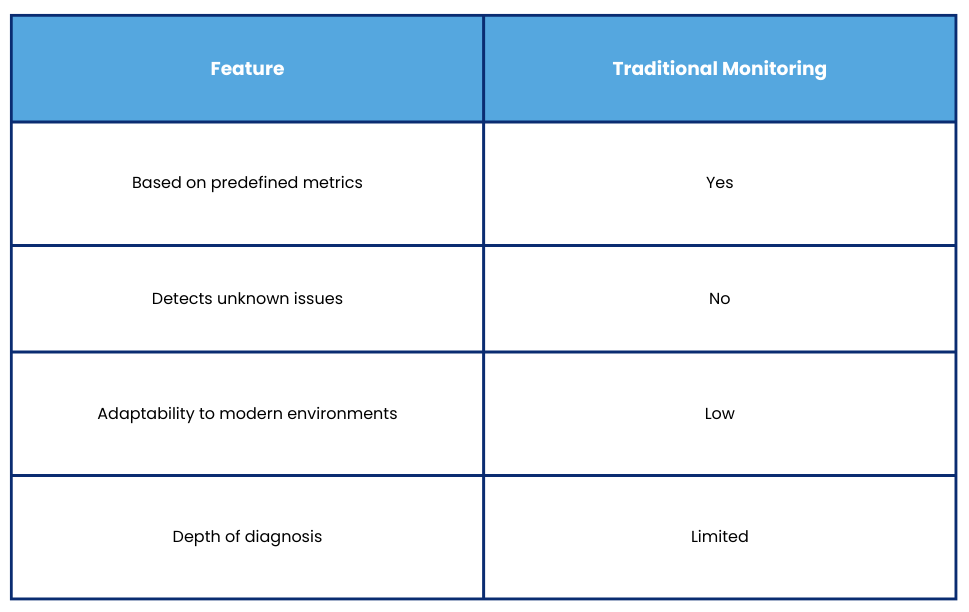
- Metrics: Numerical data that aims to reflect system performance. Metrics are required during the analysis stage to establish trends and detect anomalies before they impact systems and eventually technical or business users, including data such as the following:
- Traces: These allow engineers to track the journey of a request through a distributed system, for instance, helping to pinpoint bottlenecks and failure points in modern microservices-based applications. This data is collected using a combination of collection agents, APIs, and real-time data pipelines. Example:

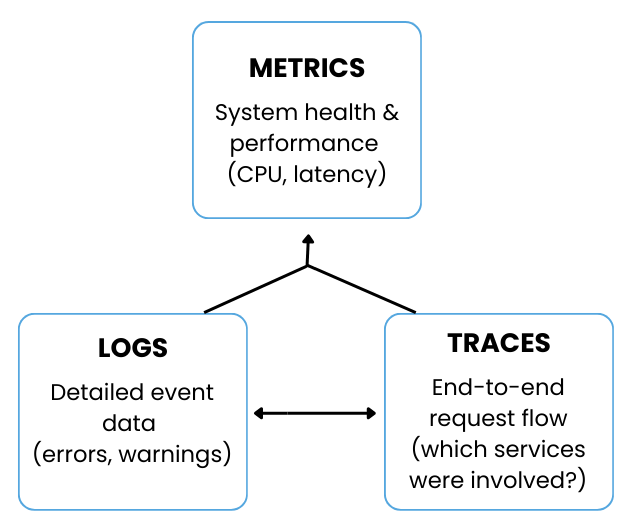
So let´s quickly see how logs, metrics, and traces work together in an Observability context: Logs tell you what happened, metrics show how things are performing over time, and traces reveal where things slow down across systems.
“Classic” monitoring focuses on static alerts and predefined metrics, while Observability enables a deeper system behavior analysis, aiming to discover unforeseen issues. In modern businesses surrounded by dynamic infrastructure environments where microservices and cloud computing are thriving, Observability is essential because systems continuously evolve and require rapid and effective diagnostics.
The following table summarises the difference: