Que es una traza y por qué se monitorizan
Cómo entender el recorrido de las peticiones en tus sistemas y controlar arquitecturas complejas
En el artículo anterior hablábamos de cómo reducir el MTTR con inteligencia artificial y de un problema que aparece en casi todos los entornos cloud modernos: cuando algo falla, el verdadero reto no es resolverlo rápido, sino entender qué está pasando dentro del sistema.
En arquitecturas distribuidas, con microservicios, APIs y múltiples dependencias, una sola acción de usuario puede atravesar decenas de servicios distintos. Y cuando no tienes visibilidad de ese recorrido, diagnosticar un problema se convierte en un proceso lento basado en suposiciones.
Ahí es donde entran las trazas, uno de los pilares de la observabilidad moderna.
Qué es una traza (sin complicarlo)
Una traza es el registro completo del recorrido que sigue una petición dentro de un sistema distribuido.
Por ejemplo: un usuario entra en una web, inicia sesión, añade un producto al carrito y finaliza una compra.
Detrás de ese proceso, el sistema puede estar interactuando con múltiples componentes: servicio de autenticación, API de catálogo, servicio de pagos, bases de datos, sistema de stock, servicios externos…
Una traza permite ver todo ese recorrido de principio a fin, como si fuera un “mapa” del flujo real de la petición dentro del sistema.
Cada paso de ese recorrido se llama “spam”, y juntos forman la historia completa de lo que ha ocurrido.
Por qué las trazas son críticas en entornos cloud modernos
El problema en las arquitecturas actuales no es que haya fallos, es que hay muchos puntos donde pueden ocurrir.
Por ejemplo, cuándo la aplicación va lenta, aparecen errores intermitentes o ciertos servicios dejan de responder, puede deberse a múltiples causas en puntos muy concretos.
Con trazas, ves exactamente dónde: qué servicio exacto está fallando, en qué punto del flujo se produce la latencia, qué dependencia está provocando el problema, cómo se propaga el error entre servicios…
Esto cambia completamente la forma de trabajar: pasas de “buscar” a “ver claramente”.
Métricas, logs y trazas: cómo se complementan
Para entender bien el valor de las trazas, hay que verlas dentro del conjunto de la observabilidad:
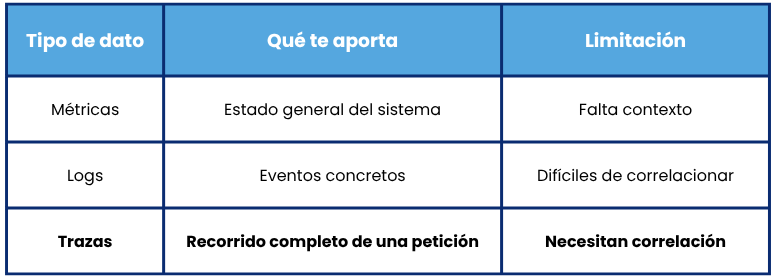
Las trazas son lo que conecta todo lo demás. Sin ellas, tienes piezas sueltas. Con ellas, tienes la narrativa completa.
Dónde empiezan realmente los problemas en producción
Hay algo importante que muchas veces se pasa por alto: los problemas en producción rara vez vienen de un único punto.
Suelen venir de pequeñas latencias acumuladas entre servicios, dependencias no evidentes, llamadas externas más lentas de lo esperado, errores que solo aparecen bajo cargas altas…
Y sin trazas, todo esto es prácticamente invisible hasta que el impacto ya es alto.
Qué cambia cuando empiezas a usar trazas correctamente
Cuando las trazas están bien implementadas, el cambio no es solo técnico, también es operativo:
- Los equipos dejan de “probar cosas” y empiezan a ver el flujo real
- Se reduce el tiempo de diagnóstico (clave para el MTTR)
- Se entienden mejor las dependencias entre servicios
Esto conecta directamente con lo que veíamos en el artículo anterior: menos tiempo entendiendo el problema = menos MTTR.
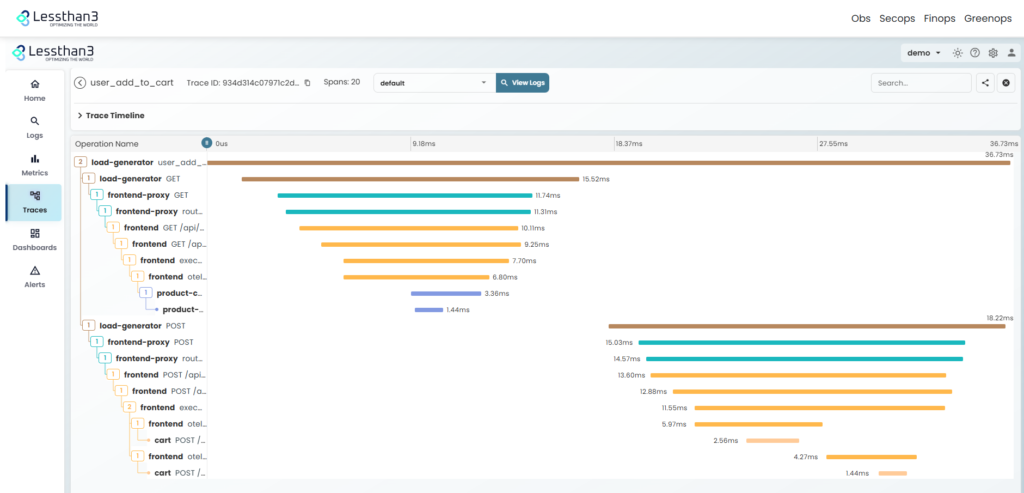
Cómo ayuda Lessthan3
En Lessthan3, las trazas no se analizan de forma aislada, sino como parte de una visión completa del sistema tecnológico o la aplicación que sea.
Nuestra plataforma permite analizar trazas en tiempo real, correlacionarse con métricas y logs, detectar patrones anómalos automáticamente y anticipar incidencias antes de que impacten en la producción y al negocio.
El objetivo no es solo ver lo que ha pasado, sino entender por qué ha pasado y qué impacto tiene en el resto del sistema.
Conclusión
Las trazas se han convertido en una pieza a la que es fundamental prestar atención en cualquier arquitectura cloud moderna. No solo permiten ver el recorrido de una petición, sino entender cómo interactúan todos los componentes de un sistema distribuido.
En el contexto actual, donde la complejidad crece constantemente, esto es clave para mantener el control.
Como ocurre con la métrica de MTTR, cuando mejor entiendes lo que ocurre dentro de tu infraestructura, más rápido puedes reaccionar y solventar o evitar fallos.
Y las trazas son precisamente eso: la forma más directa de dejar de trabajar a ciegas y empezar a ver el sistema tal y como es.